
Last week when I saw the following Tweet from the KhataBook co-founder: It got me thinking about another David vs. … More

Cars, technology, finance and fitness.
Last week when I saw the following Tweet from the KhataBook co-founder: It got me thinking about another David vs. … More
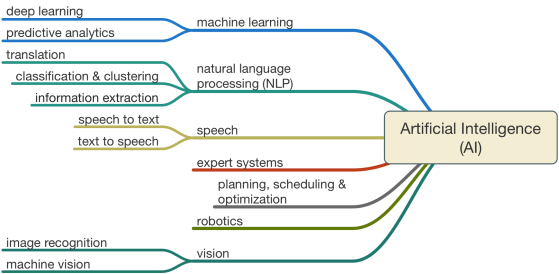
This is the 3rd of a 4-part series on the Internet of Things (IoT). As I mentioned in my first post, … More
