
This is the 3rd of a 4-part series on the Internet of Things (IoT). As I mentioned in my first post, there are 3 parts to the IoT architecture, in what I call “Triple A” IoT architecture:
- Aggregation – Building an IoT device to capture the data
- Analytics – how do you process and analyze the data (this blog post)
- Action – how do you monetize the data
Let’s continue with the previous blog post and assume you have 1000’s of air quality sensors that are sending data every minute. Now that you have 1000’s of sensors generating all this data, how do you slice and dice the data to make sense of it all. This is where your data science team would take all this data and create something useful from it.
Below is a YouTube clip of someone going through the IoT sensor data to try and build an AQI prediction algorithm.
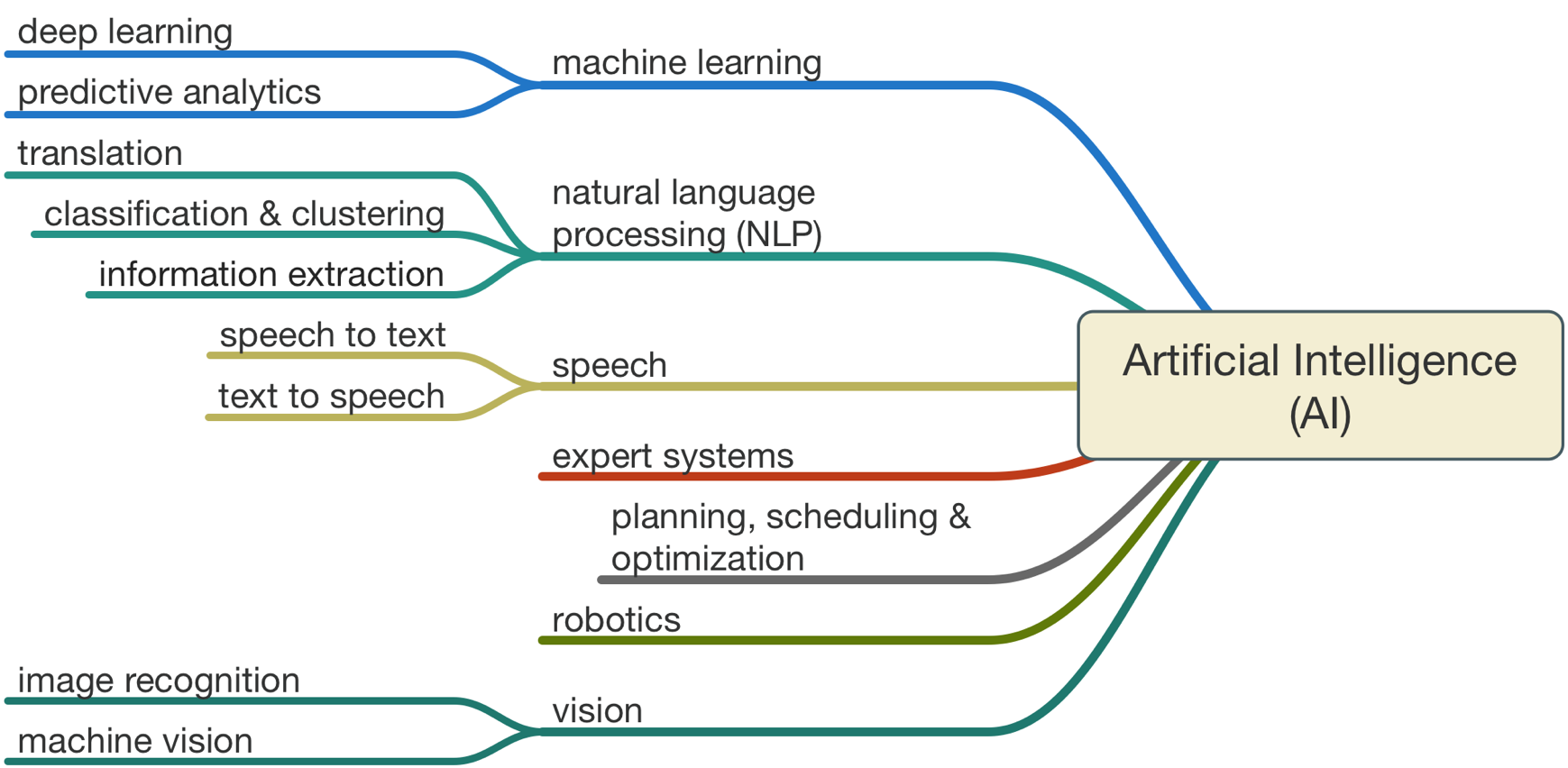
However, let’s first step back and understand all the hype around the buzzwords you might have heard like Artificial Intelligence (AI), Machine Learning (ML) and Natural Language Processing (NLP).
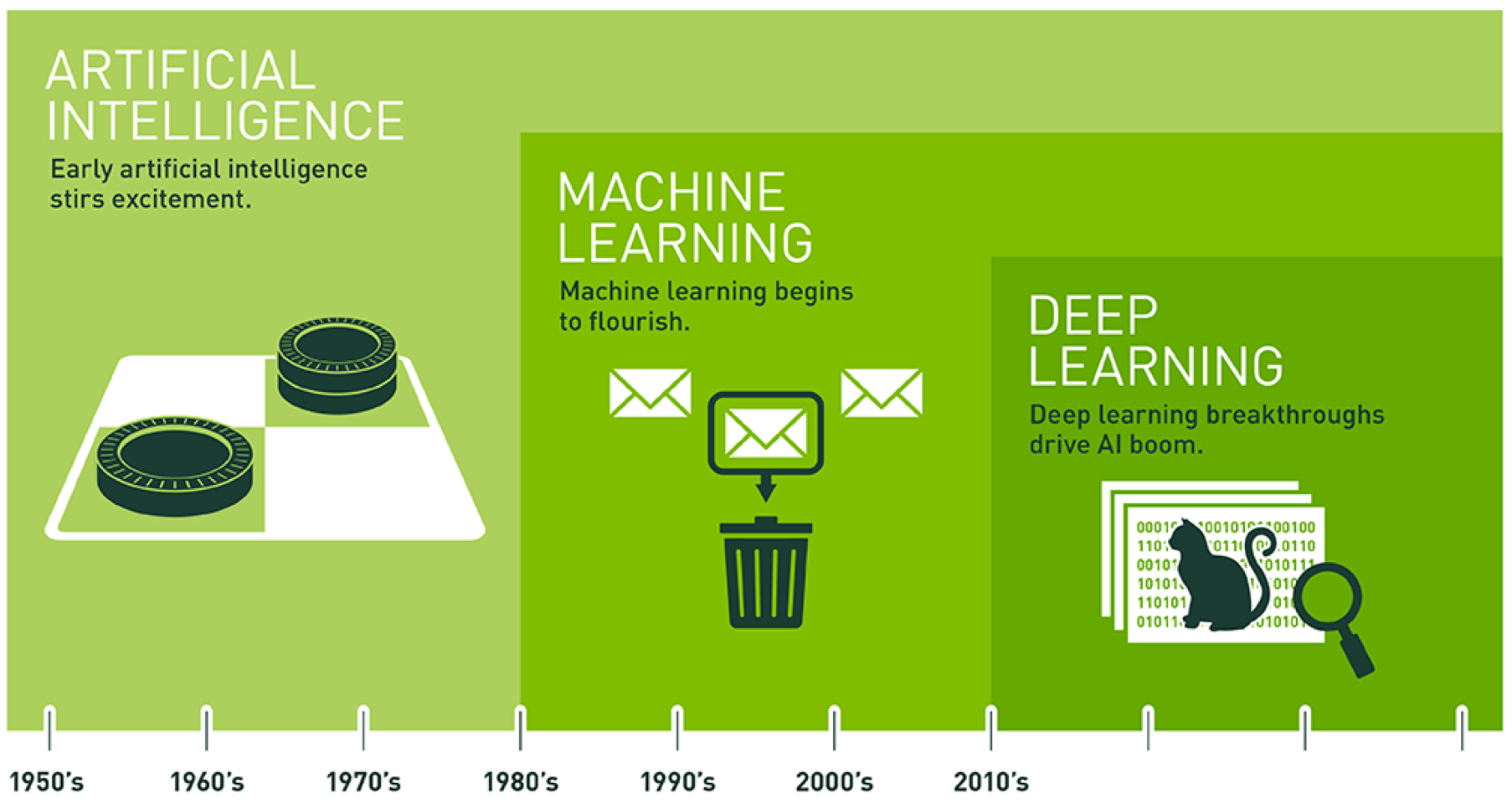
AI has been around since the 1950s and Machine Learning from the 1980s, but because of advancements in software and hardware it has caused a dramatic growth in the viability of using machine learning in a day to day setting. The basic premise is that the computer can do the thinking that was previously done by humans.
In Machine Learning if you give the computer enough training data about cats and dogs, it will be able to classify future images based on what it learned from the training data. You can go one step further and teach it to classify the breed, here is a link to see how that happens.
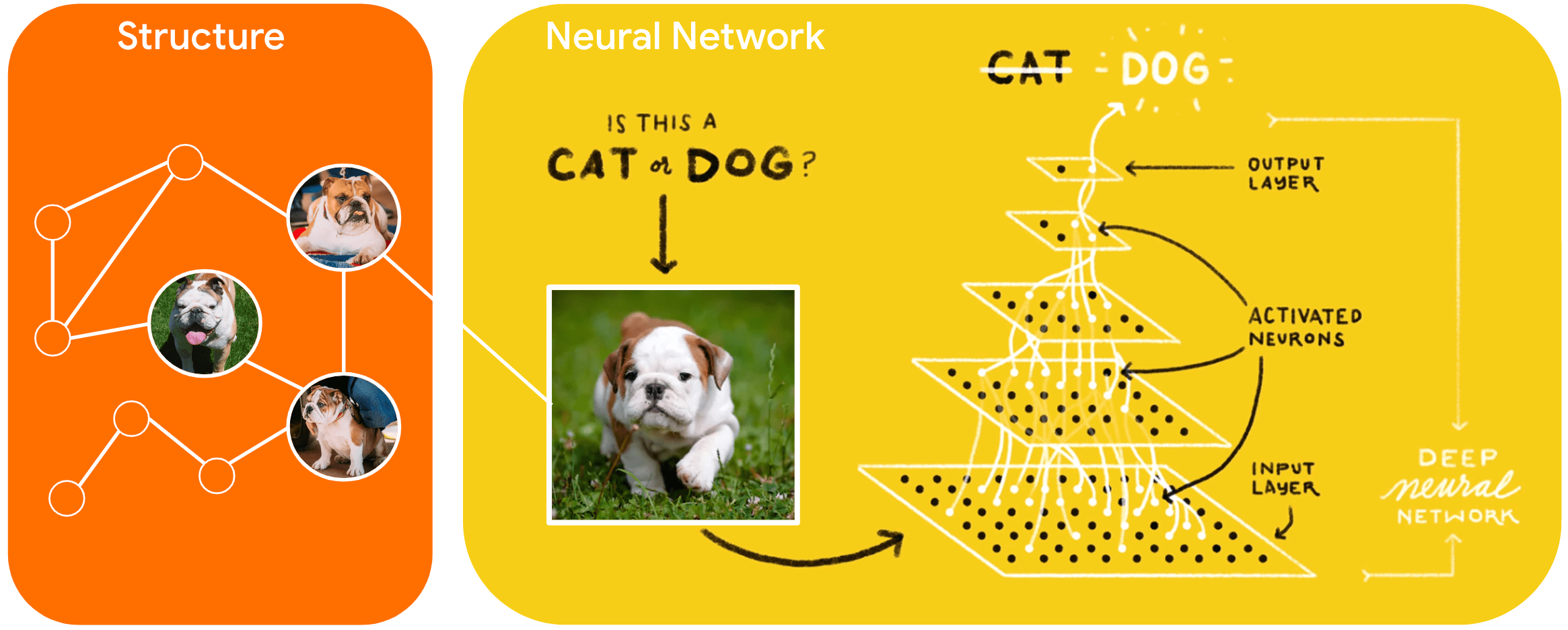
With Deep Learning, the computer would “learn” the difference of the breeds and present that data to you. This is very powerful and one of the reasons why so many startups that are involved in AI/ML are so highly valued.
In our example if you deployed 5,000 air quality sensors in Delhi and the data is sent every 60 seconds. That means in 1 hour you will have generated 300,000 “rows” of data and in 24 hours you will have 7.2 million “rows”.
Using other data points such as humidity and temperature the data science team can start to build out an air quality index (AQI). It can start to predict what the AQI levels will be based on weather patterns. Then it can push the envelope and see if there is an AQI difference between buildings in the same area. Or does the AQI level of buildings from the same builder have a consist AQI number across the city. This is really where a data scientist would come up with these scenarios to test against a subset of the data and then start to run it against all the data available.
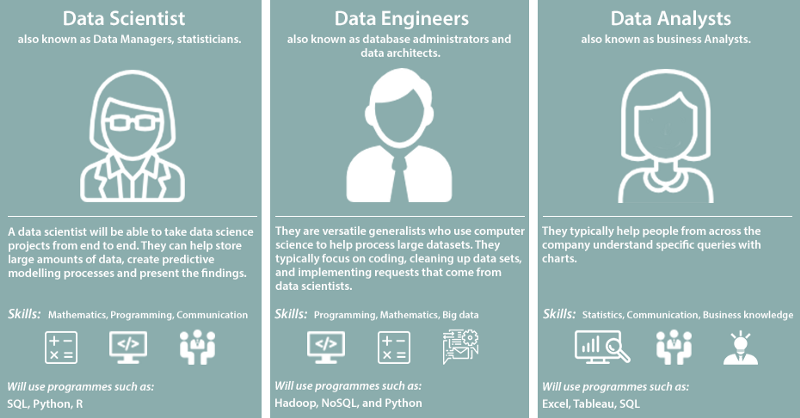
Much of what the data science team will do is based on commercials inputs from the business analysts and business development teams. Building a data science team is similar to building a tech team – there is no one size fits all. The data scientist leads the team and understands the business problem the company is trying to solve. Then the data engineers and data analysts help to create and deploy the solution. I know this is an oversimplification but for this example it will suffice.
The next and last post in this IoT series is about Action – what happens with the information that’s generated from the data science team.

Again, terrific insight. But here’s my present day concern, with the Infrastructure and technology readily available, I feel the training required for the labour force to acquire skills for matching up to these job roles is a major issue.
Major technical institution’s across the country are lagging so far behind in the curriculum being offered. And that’s just ironic for a country like ours where there’s a plethora of skilled labour but very little skill 😦
We have a large population and most seem only concerned with getting attention on TikTok!