
If you got married because of Shaadi.com, you can thank my brother-in-law Sandeep Jain and me. 30 years ago today, … More

Cars, technology, finance and fitness.
If you got married because of Shaadi.com, you can thank my brother-in-law Sandeep Jain and me. 30 years ago today, … More

I was at the Taj last month for the 5th Annual Aikya Connect Family Office Forum. 85+ single family offices … More

I have spent 30+ years in technology. I have seen multiple waves of disruption: the internet, mobile, cloud, SaaS. Each … More
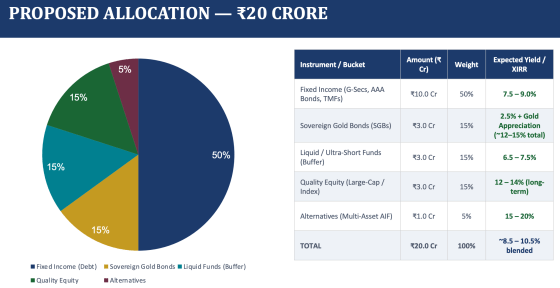
If you know me, you know I’d rather be writing about a $38.5 million Ferrari or the latest Concours d’Elegance. … More
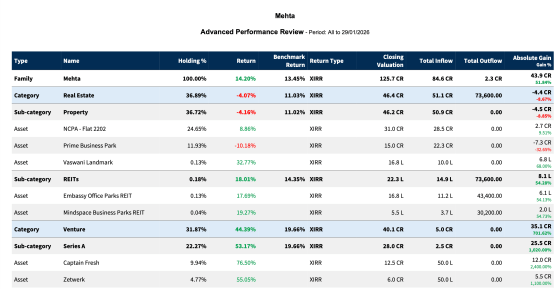
In the world of AI, everything is cool until it hits your area of expertise. I saw the recent announcement … More

Recently, MProfit took part in the Transformance Forums Family Office Summit in Bengaluru. It was a gathering of around 100 … More

I just spent 7 days at Breach Candy Hospital. Not only did the experience shift my outlook on life, but … More

Driven by rapid innovation, significant investments, and an influx of funding, AI has taken center stage in today’s media landscape. … More

Around 12 years ago I created a slide deck called the Startup Engineering Cookbook which was created to help non-technical … More
